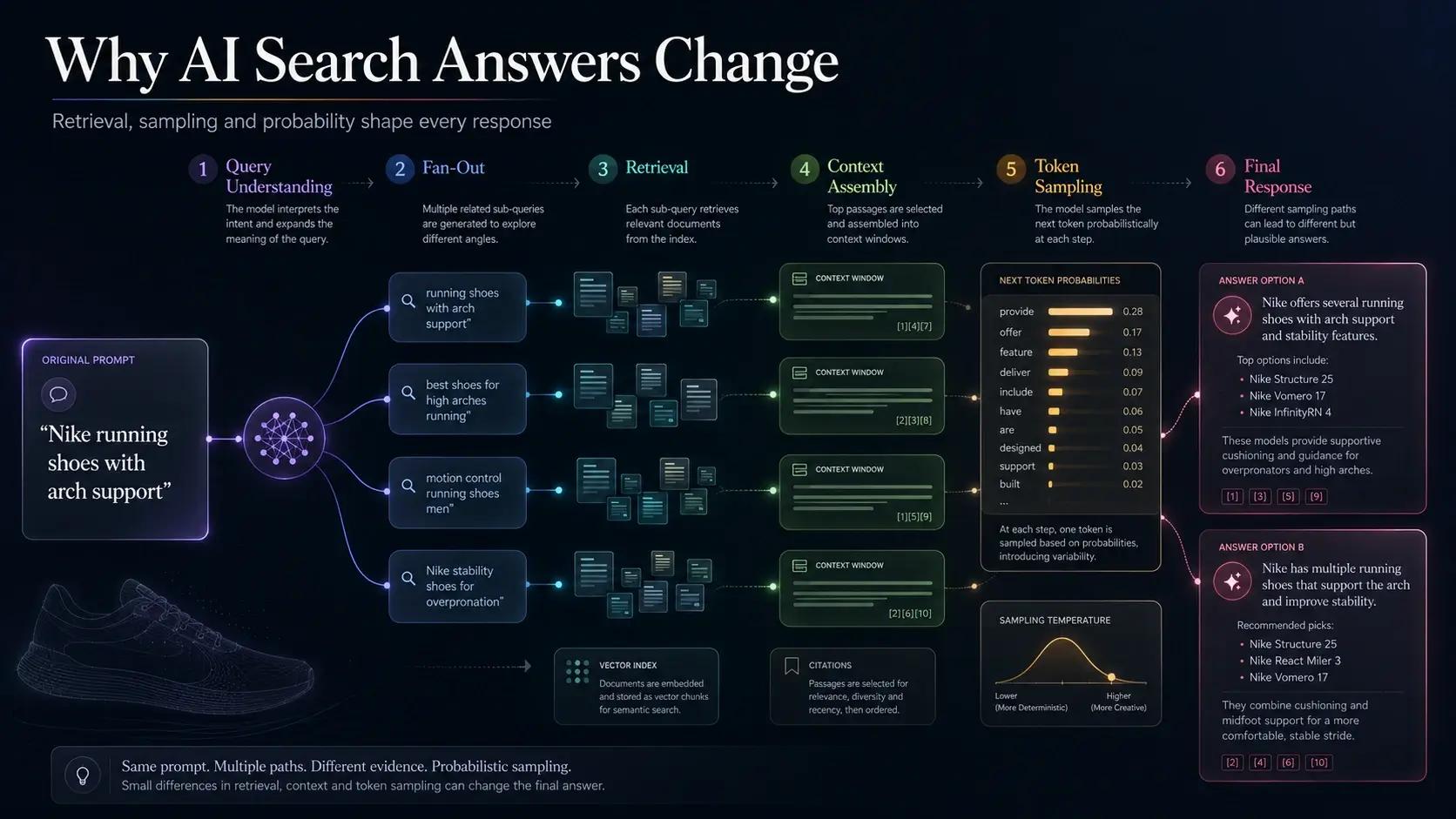
Ask an AI search engine the same question twice and you can get two different answers back. Not because the model changed its mind, but because randomness is designed into nearly every stage of the pipeline between your prompt and its response. Not a glitch. A design decision, made six times over. Here is where each one happens.
"I need a new pair of Nike running shoes for a middle aged tall man with good arch support."
The model parses intent, entities, and context:
- Entity: Nike (brand)
- Category: running shoes
- Attributes: middle aged, tall man, good arch support
The model generates multiple retrieval queries:
Each fan-out query hits the search index:
- Web pages are chunked (segmented)
- Chunks are embedded (converted to vectors)
- Top-K most semantically similar chunks are retrieved
Retrieved chunks are injected into the context window:
- System prompt
- Retrieved chunks (ranked by relevance)
- User prompt
The model predicts the next token based on the assembled context, one token at a time.
- Outputs a probability distribution over the entire vocabulary for the next token
- The top token (greedy) is rarely the only choice
- Temperature / Top-P sampling selects from the distribution
"Based on your requirements, the Nike Air Zoom Structure 24 offers excellent arch support and is available in extended sizes…"
What this means if you're optimising for AI search
None of this is a bug you can patch. It is the architecture. Six separate places inject their own variance: query parsing, fan-out, retrieval, context assembly, sampling, and citation. And the variance compounds. That is why chasing a single "AI search ranking" the way you would chase a Google position is the wrong mental model. There is no rank to hold, only odds: of being retrieved, assembled, and sampled into the answer often enough to matter. You are not optimising for a position. You are loading dice.